Amazon Elastic Compute Cloud (Amazon EC2 ki) is a web service that provides secure, resizable compute capacity in the cloud. It is designed to make web-scale cloud computing easier for developers. (source)
As data scientists, we occasionally encounter situations in which our personal laptops do not pack enough computational punch for certain tasks. Fortunately, we can rely on cloud compute resources such as Amazon Web Services (AWS) to facilitate our workflow. By tapping into cloud computational power, we can expand the limits of the data that we can process for our data science needs.
In addition to EC2, AWS also offers file storage (S3) and distributed computing (EMR), among others; detailed information about relevant AWS offerings can be found on this excellently written article, or on the AWS front page.
Here’s an agenda of the steps we’ll need to take:
- Set up an AWS account
- Set up an EC2 instance
- SSH into the EC2 instance
- Set up the EC2 instance
- Upload data into EC2
- Open a Jupyter Notebook and data science away!
- Stopping an instance
- Optional (but highly recommended): Write shell scripts to automate instance-related tasks (start/ssh/stop)
Some of these steps are outlined in the AWS EC2 documentation; this guide will replicate and extend on those steps with pictures. The documentation is extremely comprehensive (albeit slightly overwhelming to the average beginner), so I would recommend taking a look if you need to troubleshoot or want to find out more! We also assume basic familiarity with Terminal and Linux commands; check out this awesome tutorial. If you’re on Windows, you will need toinstall Git Bash and follow this tutorial on the Git Bash terminal, not on Command Prompt.
Before we get started, briefly note that there are other companies that provide cloud compute resources; most notably:
- Google: Google Cloud Platform
- Microsoft: Microsoft Azure
- IBM: IBM Cloud
However, this article will focus on Amazon’s offerings. Let’s get started!
1a. Set up a new AWS account
Pretty straightforward: head to aws.amazon.com and sign up for an account. If you’re from a participating institution, head to aws.amazon.com/education/awseducate/and enter your participating instution’s email to get free credits (which you’ll need)! Double-check that your free credits have registered on your billing page:
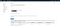

Otherwise, enter your credit card information on the Payment Methods page before moving to the next step. (We won’t actually need any credits for this tutorial, as the example will be done with the free tier; however, for realistic day-to-day work on EC2 we’ll want to pay up for more beefy compute power).
1b. Creating an IAM user
The credentials (email + password) that we made in Step 1a are known as the root user; however, AWS best practices suggest using an Identity and Access Management (IAM) user to access AWS services. This way, we can specify more granular permissions for who can access sensitive information (e.g. payment options and credit card information) or control your launched services.
Once you login to your AWS account, you’ll be greeted by this launch page:


Type “IAM” in the search field, and we’ll be greeted by the Identity and Access Management dashboard.
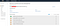

We want to create an Administrator IAM user that we will use to handle administrative tasks. Amazon lists out detailed steps here, which we will walk through in this tutorial with screenshots.
In the navigation pane of the console, choose Users, and then choose Add user.
For User name, type
Administrator.Select the check box next to AWS Management Console access, select Custom password, and then type the new user’s password in the text box. You can optionally select Require password reset to force the user to create a new password the next time the user signs in.
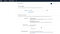

Choose Next: Permissions.
On the Set permissions page, choose Add user to group.
In the Create group dialog box, for Group name type
Administrators.For Filter policies, select the check box for AWS managed — job function.
In the policy list, select the check box for AdministratorAccess. Then choose Create group.
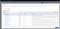

Back in the list of groups, select the check box for your new group. Choose Refresh if necessary to see the group in the list.
Choose Next: Review to see the list of group memberships to be added to the new user. When you are ready to proceed, choose Create user.
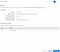

We’ve successfully created an Administrator IAM user! From now on, we’ll want to perform any administrative tasks by logging into the Administrator IAM user, as follows:
Return to the IAM dashboard. Copy the link, or optionally customize the link to show an alias instead of your AWS account ID. For the purposes of this tutorial, I’ll make my alias “junseo-tutorial”.
Sign out of AWS, and navigate to https://<your_aws_account_id>.signin.aws.amazon.com/console/ or https://<your_account_alias>.signin.aws.amazon.com/console/. You should be able to log into this with your Administrator account!
At the top right, we should be greeted by “Administrator @ <your_aws_account_id_or_alias>”. If so, we’re ready to launch set up our EC2 instance!
2. Set up an EC2 instance
Amazon offers a lot of cloud services; but for now, all we’re interested in is EC2. Search for and select EC2, and you should find yourself at the EC2 dashboard:
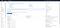

Let’s click on the Instances tab on the sidebar, which leads you to a page like this:
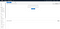

You might notice that your dashboard says “You do not have any running instances in this region.” What does this mean? Amazon hosts data centers and servers in various places across the world; in the top right of the window, you might notice that my current selected region is N. Virginia. Prices can vary by region (by rule of thumb, N. Virginia is often the cheapest for those in North America), but your latency will also be affected if you choose a sub-optimal location.
The next portion of this guide closely follows the AWS EC2 documentation.
From the console dashboard, choose Launch Instance.
The Choose an Amazon Machine Image (AMI) page displays a list of basic configurations, called Amazon Machine Images (AMIs), that serve as templates for your instance. Select an HVM version of Amazon Linux 2. Notice that these AMIs are marked “Free tier eligible.”


At this step, feel free to select different Linux distributions as desired (but probably stick with either Amazon Linux 2 AMI or Ubuntu Server 18.04). AMI selection depends on usage; for example, a deep learning engineer might choose the Deep Learning AMI, which comes with neural network frameworks pre-installed (albeit at additional cost, as it is not “Free tier eligible”).
On the Choose an Instance Type page, you can select the hardware configuration of your instance. Select the
t2.microtype, which is selected by default. Notice that this instance type is eligible for the free tier.
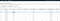

IMPORTANT: for tutorial purposes, we will proceed with a free-tier-eligible t2.microinstance; however, for our data science needs, we will most likely want to select something in the range of m5.large to m5.2xlarge, or a p2.xlarge for deep learning work. More details and pricing found here.
Choose Review and Launch to let the wizard complete the other configuration settings for you.
On the Review Instance Launch page, choose Launch.

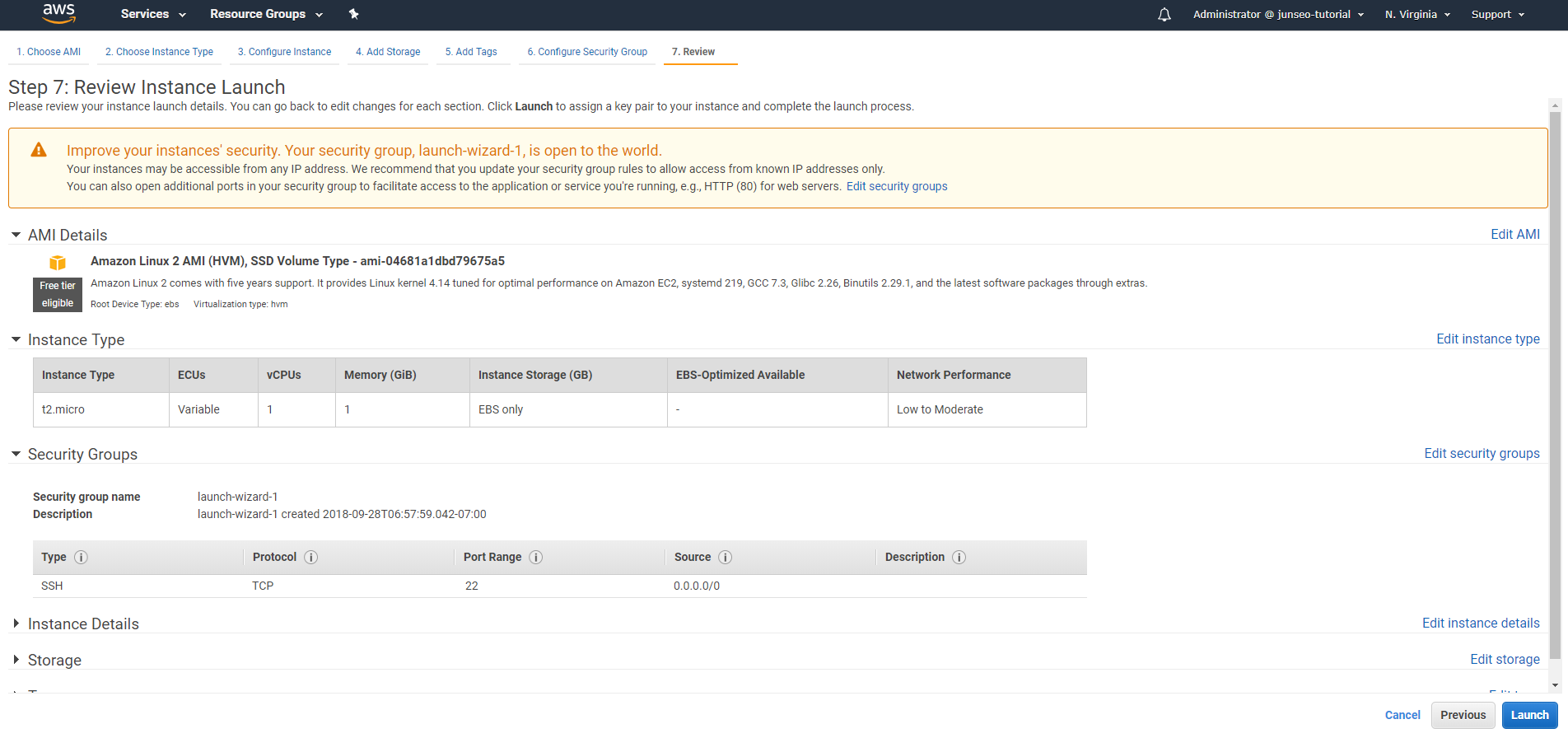
We skip a couple configuration steps here; notably, step 4 allows us to expand the storage that we configure our EC2 instance with. Let’s proceed for now; this is something we can change later.
In order to connect to our EC2 instance, we’ll need a key pair. Select “Create a new key pair” from the dropdown, and we’ll name it tutorial. Download, and make careful note of where you save it! We’ll need this soon.

Click “Launch Instances”; congratulations on launching your first EC2 instance!
3. SSH into the EC2 instance
Before you start this step, make sure your EC2 instance has passed all of its status checks:

The first task is to make sure that only we can read our private key pair file tutorial.pem. Run the following command:
$ chmod 400 <path-to-key-pair>/tutorial.pem(For Windows Subsystem for Linux users, the key pair file must be placed in the Linux filesystem. In other words, the absolute path of tutorial.pem must not start with /mnt/; instead, copy the file to the Linux filesystem (e.g. ~/tutorial.pem), then run the chmod command.)
Let’s return to the EC2 dashboard; select your instance, then click the “Connect” button. We are greeted by a help pop-up:

Copy the example text, and run the command in Terminal (with the correct path to your tutorial.pem file). You should be greeted by a warning such as the following:
The authenticity of host 'ec2-54-89-157-53.compute-1.amazonaws.com (<no hostip for proxy command>)' can't be established.
ECDSA key fingerprint is SHA256:KwZ6qhAe4OjRu8bGQdkpXQqSPMnN+D8OKzanBelYx5o.
Are you sure you want to continue connecting (yes/no)?Type yes, and hit Enter. The response will be similar to:
Warning: Permanently added 'ec2-54-89-157-53.compute-1.amazonaws.com' (ECDSA) to the list of known hosts.And we’re in!
4a. Set up the EC2 instance
First things first: we’ll want to update all the existing packages in our EC2 instance. Run sudo yum update (or sudo apt-get update if you selected an Ubuntu instance), and type y when prompted. This might take a couple minutes, so now’s a great time to grab a quick snack.
Next, we’ll want to set up Python3. Ubuntu 18.04 instances should come with this pre-installed, but we’ll need to do this manually for Amazon Linux 2 instances, which come with only Python2. This can be done with sudo yum install python3 ; this will also install pip3 on your EC2 instance.
4b. Create a virtual environment
For reproducibility, we want to use virtual environments that can keep track of all the packages we use in a project. There are a lot of ways to create virtual environments in Python (a lot), but starting from Python 3.3 there’s a built-in library that takes care of this for us.
Let’s create a new directory test, and inside the folder we’ll want to run the following command:
$ python3 -m venv <name-of-virtual-environment>By convention, people often name their virtual environment .env , or less frequently, .venv, env, or venv . I recommend sticking with one of the first two, since it’ll be a hidden directory and stay out of the way.
We can activate the virtual environment using source .env/bin/activate ; then we should be greeted with confirmation in our Terminal that the virtual environment is activated.


From here, we can install all the Python packages we might need. A good place to start is the following list:
- pandas
- numpy
- matplotlib
- seaborn
- scikit-learn
- statsmodels
- jupyter

Lastly, to adhere to best practice, let’s save our virtual environment settings. Run the following:
$ pip freeze > requirements.txtThis creates a requirements.txt file that contains a list of all the Python package versions that we’re using in our virtual environment; this allows other developers to recreate the exact same working conditions by running pip install -r requirements.txt with the same requirements.txt file.
Our EC2 instance is all set up! But how do we work with data?
5. Upload data into EC2
We have a couple options to access data in EC2:
- Download data from web links
- Upload data into AWS S3, and access from Jupyter Notebooks
- Upload data from our laptops into our EC2 instance’s storage
We’ll proceed with the third option. Let’s establish the following scenario:
- We want to transfer a data file
data.csvfrom our current working directory to our EC2 instance at directory~/test - Private key pair is stored at
~/tutorial.pem - EC2 instance user name is
ec2-user - EC2 public DNS is
ec2–54–89–157–53.compute-1.amazonaws.com
Information regarding the last two can be found on the “Connect” help pop-up that appeared in Step 3.
Open a new Terminal tab/window; this should open in our local computer. Run the following command from this local Terminal:
$ scp -i <key-pair-file> <data-file> <ec2-username>@<ec2-public-dns>:<ec2-directory>For example, the above scenario would lead us to:
$ scp -i ~/tutorial.pem data.csv ec2-user@ec2-54-89-157-53.compute-1.amazonaws.com:~/test
Going back to the Terminal tab/window for the EC2 instance, we can check that the file was correctly uploaded:


6. Open a Jupyter Notebook
Next, we’ll want to open a Jupyter Notebook and get started. We might be familiar with the jupyter notebook command when working locally; we can try executing this from the EC2 instance terminal (make sure you’re in your virtual environment).


The error (indicated by the yellow line in the picture above) indicates that there’s no web browser found. There are two ways to get around this:
- Forward the EC2 instance’s
8888port to the8888port on our personal machines (source) - Configure the EC2 instance to set up a Jupyter server that can be accessed via the Public DNS (source)
The first option is the simpler solution, so we’ll walk through this below.
We can specify this when we ssh. First, let’s return to our local terminal using the exitcommand. We can then modify our sshcommand from earlier to accommodate port forwarding:
$ ssh -i <key-pair-file> -L <local-port>:localhost:<ec2-port> <ec2-username>@<ec2-public-dns>So for my particular EC2 instance, I would run the following command:
$ ssh -i ~/tutorial.pem -L 8888:localhost:8888 ec2-user@ec2-54-89-157-53.compute-1.amazonaws.comThen we can cd into our project directory, activate the virtual environment (source .env/bin/activate), and launch the Jupyter Notebook with no browser (jupyter notebook --no-browser). Open the output link in your local browser, and we should be greeted by the Jupyter Notebook interface!

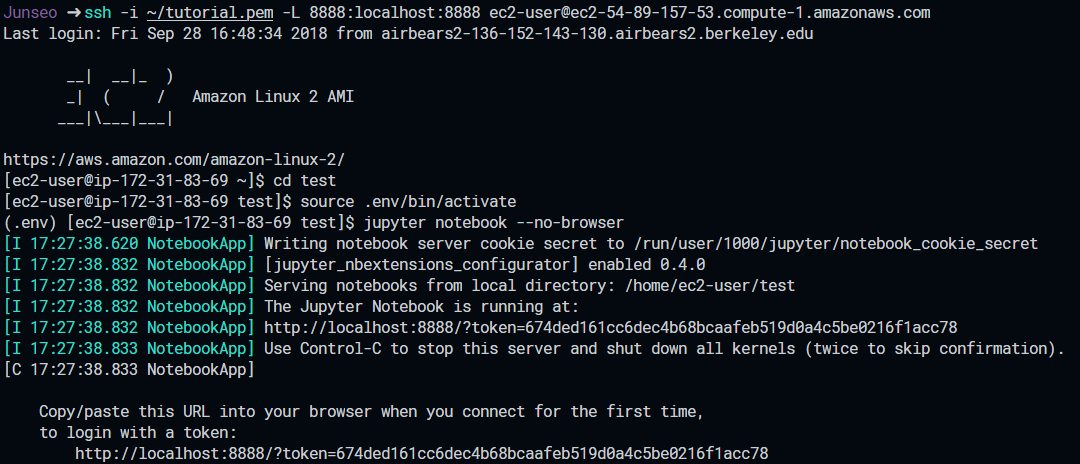

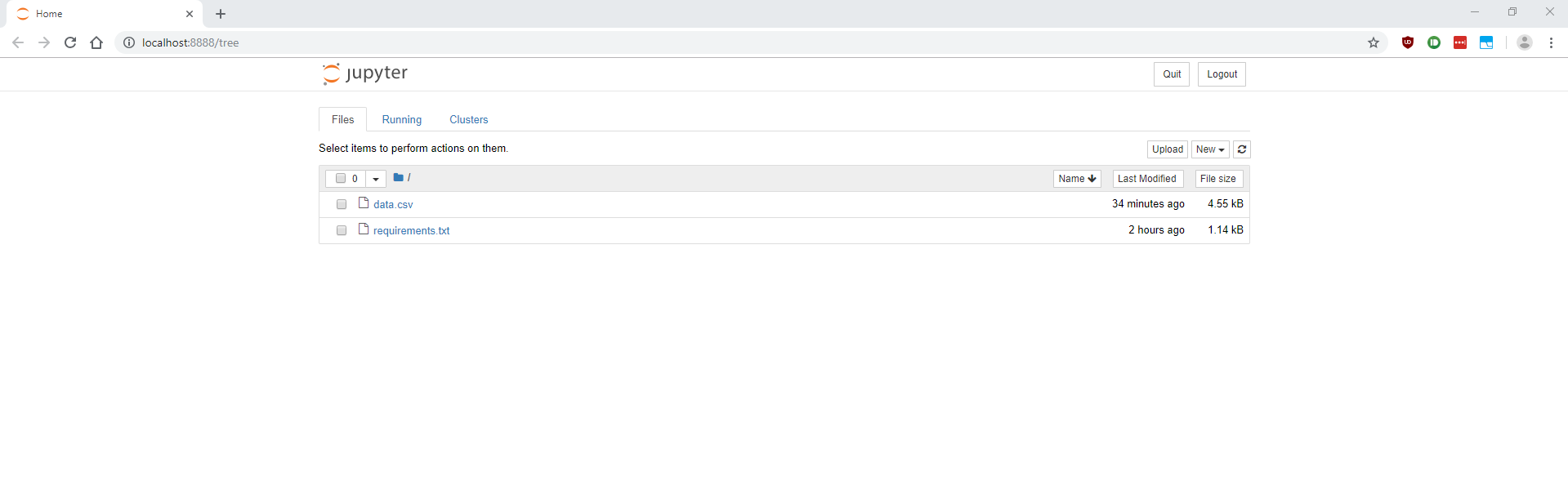
From here, we can work as we would on our local machines.
7. Stopping an instance (IMPORTANT!)
If you’ve made it this far down the tutorial, congratulations! You now have a way to access Jupyter Notebooks on AWS EC2 instances. For the purposes of the tutorial, we selected a free tier instance t2.micro; however, we did note that our data science pipelines would most likely require a paid instance with higher specs (e.g. m5.large). The cost is computed based on how long you use the instance; in other words, we want to shut down the instance when we’re not using it so that we don’t rack up an absurdly high AWS bill.
Return to the EC2 Instance dashboard, and select your instance. Click the “Actions” button, and under “Instance State”, select “Stop”. Do not select “Terminate”; this will erase your entire EC2 instance.

When you want to return to work, you can follow the same steps and click “Start” to launch up your EC2 instance. You might note that this will quickly become tedious; thankfully, we can set up an easier way to do this from Terminal…
8. (Optional but highly, highly recommended) Write shell scripts to run
instance-related tasks (start/ssh/stop)
One way to automate tasks is to use the AWS Command Line Interface (AWS CLI) to run tasks from Terminal. First, we’ll want to install the AWS CLI on our local machine:
$ pip install awscli --upgrade --userIf you encounter issues installing awscli, try creating a virtual environment (as outlined in Step 4b) on your local machine to isolate the Python dependencies.
After installing, you may need to add the path to the executable variable to your PATH file; steps to do so are outlined in the following links:
From there, let’s double-check that everything is installed correctly by running aws --version; output should look like:
aws-cli/1.16.20 Python/3.6.6 Linux/4.4.0-17758-Microsoft botocore/1.12.10Perfect; now we’ll want to configure our AWS CLI. Let’s return to the IAM console and click on the Users tab; from there, we can click into the Administrator user (which we set up earlier) to set up an access key.


Click on the Security Credentials tab and select “Create access key”.

Download your access key CSV, and store it someplace safe. Don’t share this or post it anywhere online! The access key ID and secret access key will grant you access to an AWS account; sharing this compromises your account security.
Return to your local Terminal and enter aws configure. This should prompt you to enter the following:
- AWS Access ID Key (found in your CSV)
- AWS Secret Access Key (found in your CSV)
- Default region name: Recall that we selected a region for our EC2 instance earlier. Enter this region’s code (a table can be found here); for example, for N. Virginia I would enter
us-east-1. - Default output format:
json
To verify that this ran correctly, run aws ec2 describe-instances --output table; this should output a table such as the following.


The fields in the “Instance” section should match the instance that we launched earlier; verify that this is the case by comparing the InstanceId and PublicDnsName fields shown in the Terminal output to the values shown on the EC2 Management Console website.
We can now use the InstanceID to control granular details about our specific EC2 instance from Terminal. Here are a few helpful commands (you can always add --output table at the end for a prettier output format instead of the default json):
#### Check instance status (running, starting, stopped, etc)
$ aws ec2 describe-instance-status --instance-ids <your-instance-id>#### Start instance
$ aws ec2 start-instances --instance-ids <your-instance-id>#### Stop instance
$ aws ec2 stop-instances --instance-ids <your-instance-id>
To facilitate our workflow, we can write shell scripts with these commands. I like to make shell scripts in a separate folder. For example, I might make a folder scripts that contains a shell script describe-instance-status.sh containing the first command listed above. Then, instead of typing out the commands each time, I can simply execute the script by typing scripts/describe-instance-status.sh in my local Terminal.
In the same spirit, we can also create shell scripts for the long commands that we saw earlier; namely, the ssh command that we used to connect to our EC2 instance and also open the 8888 port. This way, we simplify our workflow considerably and save ourselves a lot of time!
One important conceptual thing to note: recall that when we set up the Administrator user, we came across the following configuration screen (the same image we saw earlier in this guide):
When we initially set up the Administrator user, we did not select the “Programmatic access” option. Just now, we went back and enabled this programmatic access by generating an Access Key ID and secret access key for the Administrator user. For future users that you may create, feel free to enable programmatic access in the User creation process (instead of going back to do it later); this guide spun off the programmatic access into a separate step for clarity.
Congratulations!
You’ve accomplished the following in this tutorial:
- Set up an AWS account
- Created an Administrator user
- Launched an EC2 instance
- Access the EC2 instance using
ssh - Create a virtual environment in the EC2 instance and set up the virtual environment for data science work on Jupyter Notebooks
- Upload a file from your local machine to your EC2 instance
- Configure your local machine to access the EC2 instance for a streamlined workflow
That’s a lot to take in, so be proud of yourself! The exciting news is, there’s still a lot more left to learn; we’re just scraping the tip of the settings. Be sure to scourge the EC2 documentation to set up your EC2 instance to fit your exact needs, the documentation for AWS IAM for a more comprehensive understanding of Users/Roles/Groups, AWSCLI documentation for a more detailed understanding of how to manipulate AWS services from the command line, and documentation for S3 for an affordable long-term storage solution.
Not only that, but AWS offers many more services! Check them out here; some of these (such as Elastic MapReduce or Relational Database Service) might come handy in the data science workflow.
Comments
Post a Comment