Caching in a Node.js application using the Redis data store
In this article, we are going to implement caching in a node js application using Redis, but, before we delve into the implementation details, let’s explore what caching is and how it can help the performance of our application.
What is caching?
Caching is the process of storing copies of files in a cache or a temporary storage location so that they can be accessed more quickly.- Cloudflare
Now that we understand what caching is, let’s explore the reason for caching.
Why do we cache?
Given many super fast services and options available for users on the Internet today, you don’t want your application to take too long to respond to users’ requests or you risk the chance of your users dumping your service for a competitor and keep your bounce-rate growing instead of your revenue.
Below are a few of the reasons we cache:
To save cost. Such as paying for bandwidth or even volume of data sent over the network.
To reduce app response time.
In general, caching done the right way will improve the performance of our application and lead to a win-win situation for us and our users.
Prerequisites
To follow through this tutorial you must have the following installed on your computer
Node JS
NPM
Postman/Web Browser
Code Editor (VsCode)
If you don’t have Node installed just head on to the official Node.js website to get a copy of node js for your platform. Once you install node.js you will automatically have npm installed.
Getting Started
To get started, create a new directory for the application by running the following command on the terminal:
cd desktop && mkdir node-caching && cd node-caching
The commands above
cd desktop - navigate to the desktop directory
mkdir node-caching - create a new directory named “node-caching”
cd node-caching - navigate into the newly created node-caching directory
Initialize the directory to create a package.json file by running
npm init -y
Install dependencies
For this project we will be using Redis, axios and Express Framework for Node.js, so let’s install them by running the following:
npm install express redis axios
Open the newly created folder in your editor of choice. Your folder structure should now look like the one below:
Folder structure
Create a simple Express server as shown below:
const express = require('express');
const app = express();
const port = 3000;
app.listen(port, () => {
console.log(`Server running on port ${port}`);
});
module.exports = app;
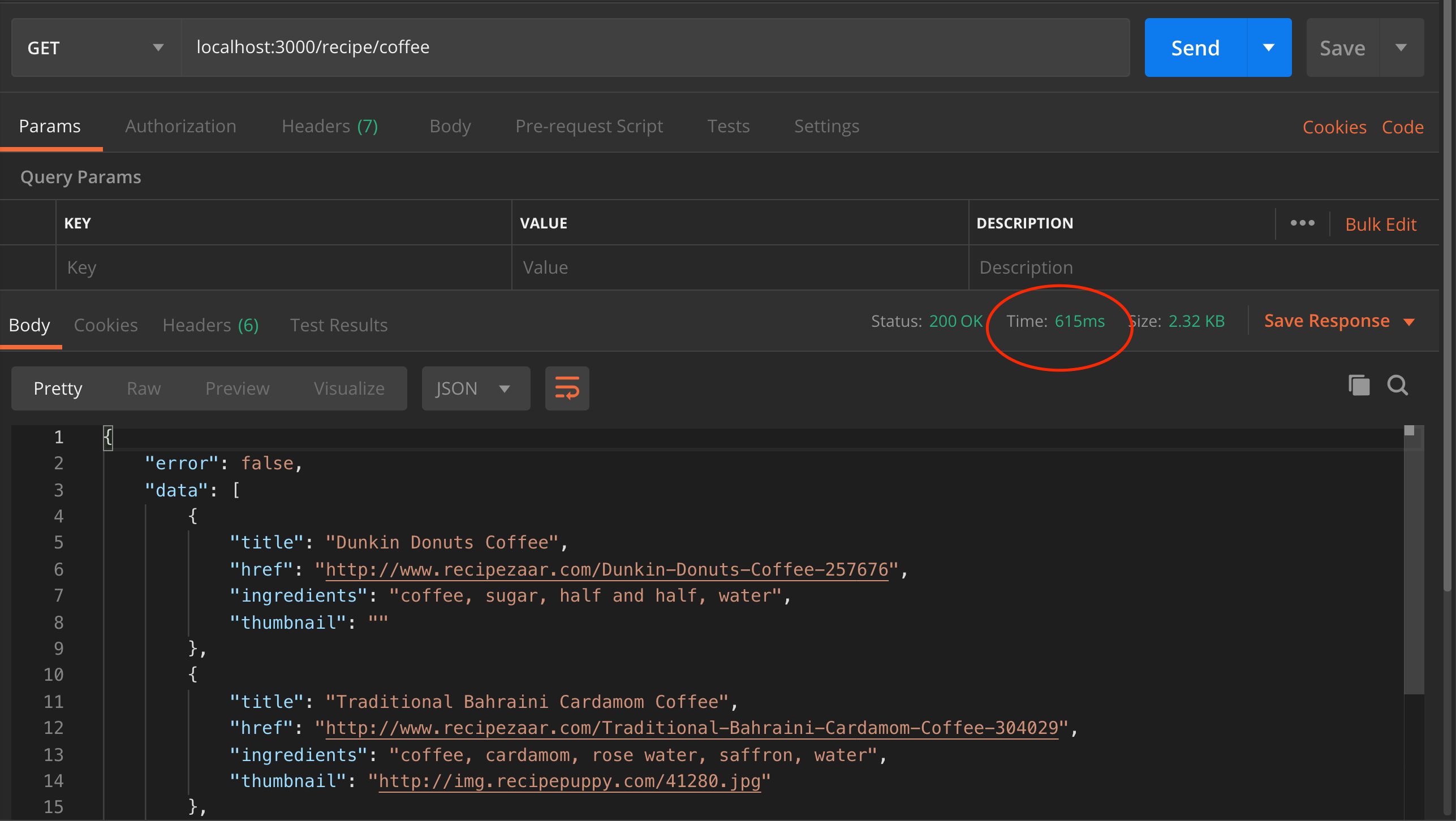
Start the server by running node index.js and open postman to make a request to the recipe endpoint
As we can see, the request completed in 615ms which is quite a long time to fetch data that doesn’t change often. We will improve this by implementing caching using Redis.
To be able to take full advantage of Redis offerings, we need to get Redis by compiling it directly from source. To do this kindly run the following command on your terminal:
Now that we have correctly setup redis, the next thing is to use it in our application to improve it by reducing the turn around time of request and response.
Add the following changes to index.js file
const express = require('express');
const axios = require('axios');
const redis = require('redis');
const app = express();
const port = 3000;
// make a connection to the local instance of redis
const client = redis.createClient(6379);
client.on("error", (error) => {
console.error(error);
});
app.get('/recipe/:fooditem', (req, res) => {
try {
const foodItem = req.params.fooditem;
// Check the redis store for the data first
client.get(foodItem, async (err, recipe) => {
if (recipe) {
return res.status(200).send({
error: false,
message: `Recipe for ${foodItem} from the cache`,
data: JSON.parse(recipe)
})
} else { // When the data is not found in the cache then we can make request to the server
const recipe = await axios.get(`http://www.recipepuppy.com/api/?q=${foodItem}`);
// save the record in the cache for subsequent request
client.setex(foodItem, 1440, JSON.stringify(recipe.data.results));
// return the result to the client
return res.status(200).send({
error: false,
message: `Recipe for ${foodItem} from the server`,
data: recipe.data.results
});
}
})
} catch (error) {
console.log(error)
}
});
app.listen(port, () => {
console.log(`Server running on port ${port}`);
});
module.exports = app;
First we created a redis client and link it with the local redis instance using the default redis port (6379)
const client = redis.createClient(6379);
Then, in the /recipe route handler, we tried to get the appropriate matching data to serve the request by checking for the key in our redis store. If found, the result is served to the requesting client from our cache and then we don’t have to make the server request anymore.
// Check the redis store for the data first client.get(foodItem, async (err, recipe) => { if (recipe) { return res.status(200).send({ error: false, message: `Recipe for ${foodItem} from the cache`, data: JSON.parse(recipe) }) }
But if the key is not found in our redis store, a request is made to the server and and once the response is available, we store the result using a unique key in the redis store:
const recipe = await axios.get(`http://www.recipepuppy.com/api/?q=${foodItem}`);// save the record in the cache for subsequent request client.setex(foodItem, 1440, JSON.stringify(recipe.data.results));
Hence, subsequent requests to the same endpoint with the same parameter will always be fetched from the cache so long the cached data has not expired. The setex method of the redis client is used to set the key to hold a string value in the store for a particular number of seconds which in this case is 1440 (24 minutes). Full list of available redis commands and options can be found here: https://redis.io/commands
Testing the application
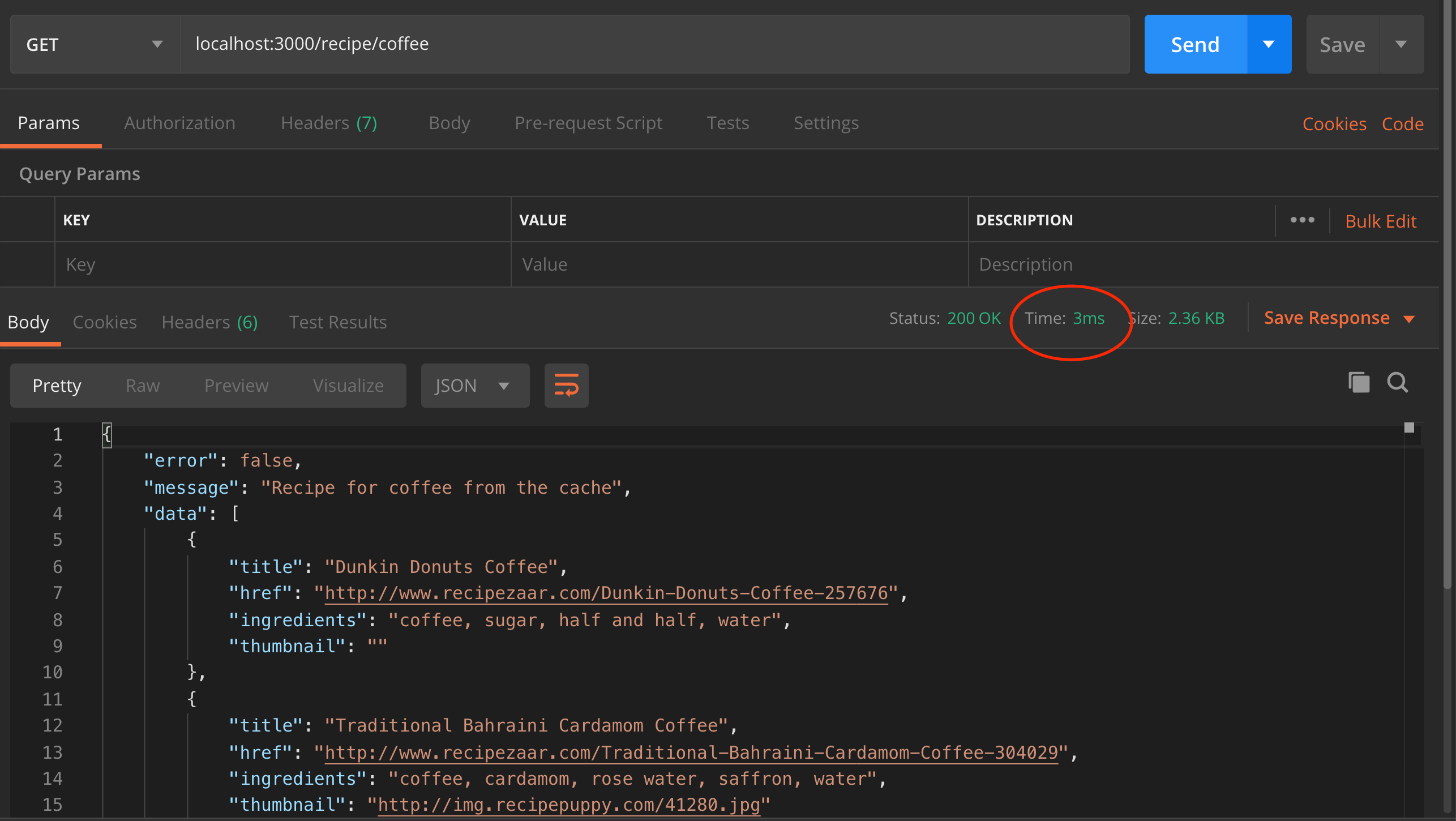
Now let’s test the application after implementing cache. Open postman and make a request to the same endpoint as before.
Again, because the key is not found in the cache the request is sent to the server which takes 566 ms to complete. Since the key didn’t exist in the cache before, it is now saved in the cache and subsequent requests with the same data will be fetched from the cache which makes it faster, and also reduces the load on the server. Below is the response time after the cache:
As we can see above, it took a blazing 3ms for the request to be completed because it was fetched from the cache.
Now tell me, don’t you want to start caching already?
Kindly note that this is just a tip of the iceberg of what we can do with redis and I recommend that you consult the official documentation https://redis.io/documentation to enjoy full capabilities of this amazing data store.
Introduction Let’s Encrypt is a Certificate Authority (CA) that provides an easy way to obtain and install free TLS/SSL certificates , thereby enabling encrypted HTTPS on web servers. It simplifies the process by providing a software client, Certbot, that attempts to automate most (if not all) of the required steps. Currently, the entire process of obtaining and installing a certificate is fully automated on both Apache and Nginx. In this tutorial, you will use Certbot to obtain a free SSL certificate for Apache on Ubuntu 18.04 and set up your certificate to renew automatically. This tutorial will use a separate Apache virtual host file instead of the default configuration file. We recommend creating new Apache virtual host files for each domain because it helps to avoid common mistakes and maintains the default files as a fallback configuration. Prerequisites To follow this tutorial, you will need: One Ubuntu 18.04 server set up by following this initial ...
1. Local Storage Events You might have already used LocalStorage, which is accessible across Tabs within the same application origin. But do you know that it also supports events? You can use this feature to communicate across Browser Tabs, where other Tabs will receive the event once the storage is updated. For example, let’s say in one Tab, we execute the following JavaScript code. window.localStorage.setItem("loggedIn", "true"); The other Tabs which listen to the event will receive it, as shown below. window.addEventListener('storage', (event) => { if (event.storageArea != localStorage) return; if (event.key === 'loggedIn') { // Do something with event.newValue } }); 2. Broadcast Channel API The Broadcast Channel API allows communication between Tabs, Windows, Frames, Iframes, and Web Workers . One Tab can create and post to a channel as follows. const channel = new BroadcastChannel('app-data'); channel.postMessage(data); And oth...
Introduction Streams are one of the major features that most Node.js applications rely on, especially when handling HTTP requests, reading/writing files, and making socket communications. Streams are very predictable since we can always expect data, error, and end events when using streams. This article will teach Node developers how to use streams to efficiently handle large amounts of data. This is a typical real-world challenge faced by Node developers when they have to deal with a large data source, and it may not be feasible to process this data all at once. This article will cover the following topics: Types of streams When to adopt Node.js streams Batching Composing streams in Node.js Transforming data with transform streams Piping streams Error handling Node.js streams Types of streams The following are four main types of streams in Node.js: Readable streams: The readable stream is responsible for reading data from a source file Writable streams: The writable stream is re...







Comments
Post a Comment