The top reasons for using Slonik are:
- Promotes writing raw SQL.
- Discourages ad-hoc dynamic generation of SQL.
- Assertions and type safety
- Safe connection handling.
- Safe transaction handling.
- Safe value interpolation 🦄.
- Detail logging.
- Asynchronous stack trace resolution.
- Middlewares.
It took a couple of iterations, but we got there – the best Node.js client for PostgreSQL. 🚀
Note: Using this project does not require TypeScript or Flow. It is a regular ES6 module. Ignore the type definitions used in the documentation if you do not use a type system.
Battle-Tested 👨🚒
Slonik began as a collection of utilities designed for working with node-postgres. I continue to use node-postgres as it provides a robust foundation for interacting with PostgreSQL. However, what once was a collection of utilities has since grown into a framework that abstracts repeating code patterns, protects against unsafe connection handling and value interpolation, and provides rich debugging experience.
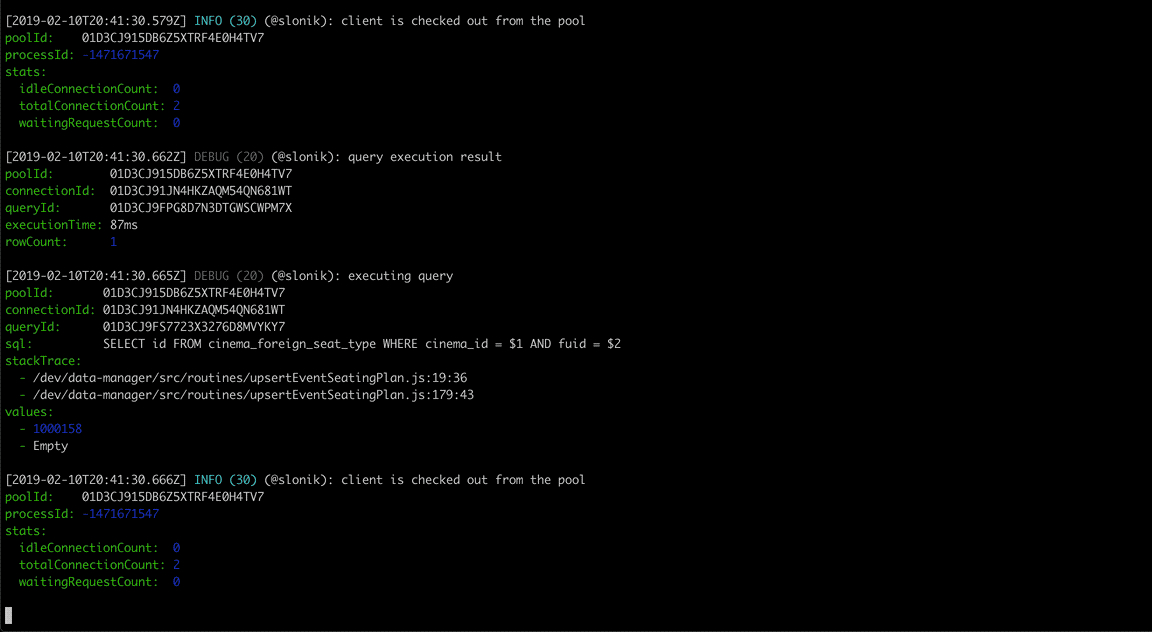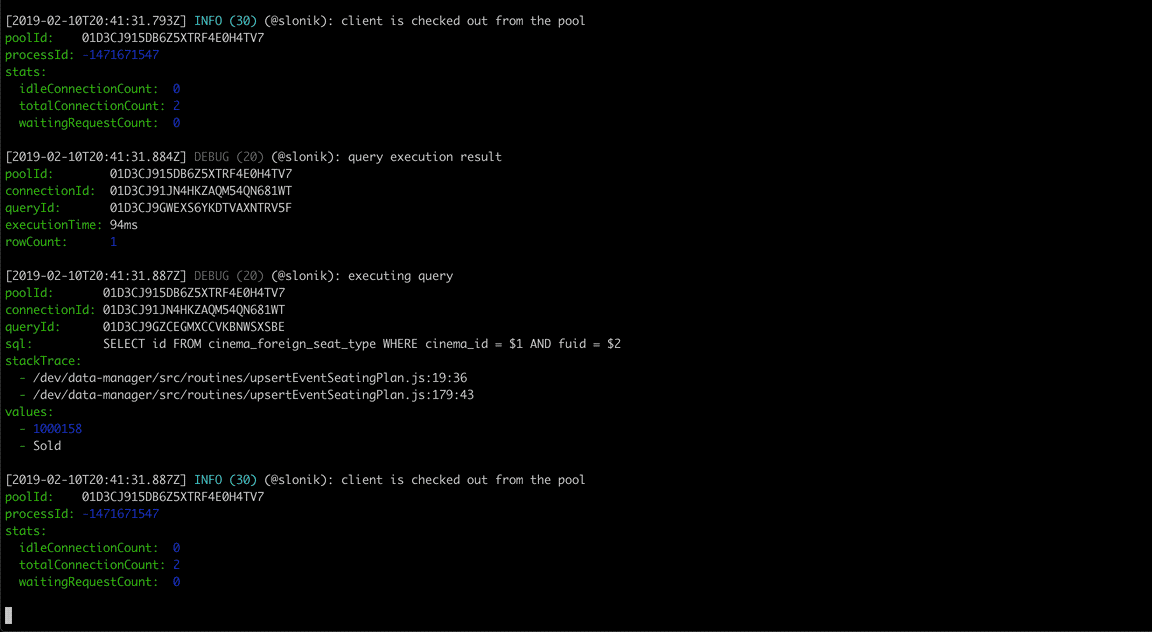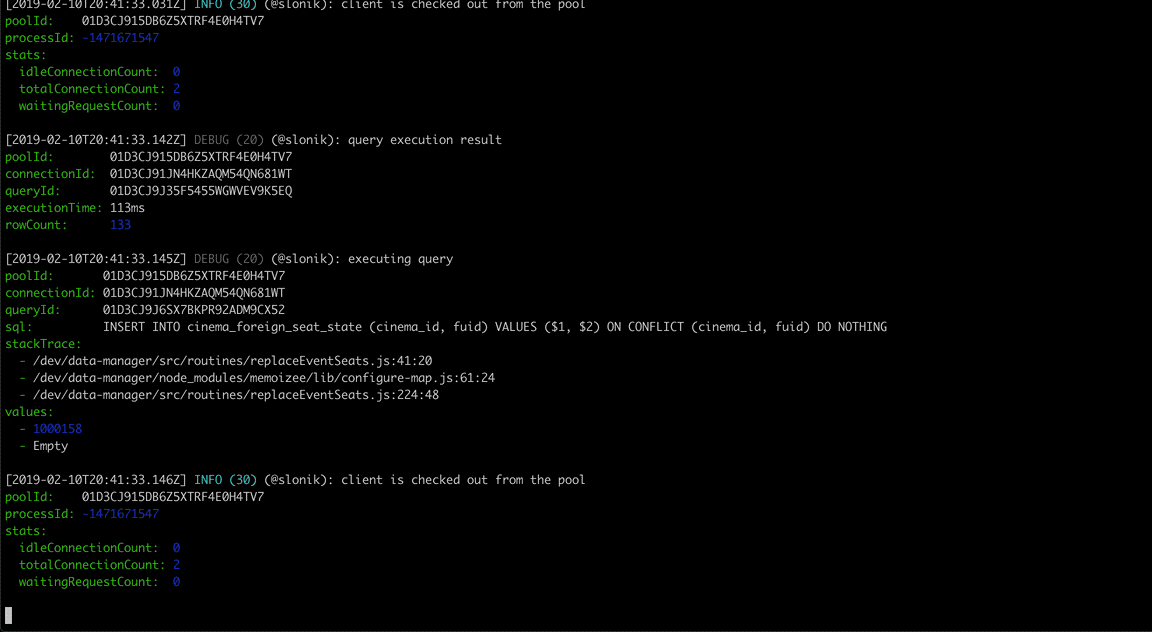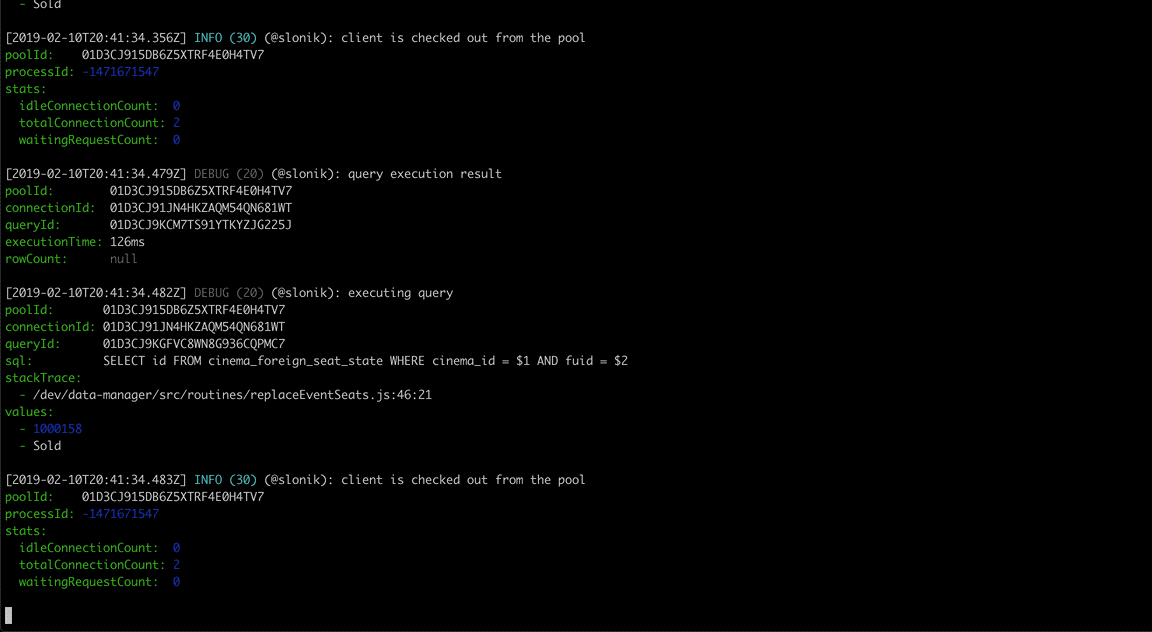

Slonik has been battle-tested with large data volumes and queries ranging from simple CRUD operations to data-warehousing needs.
Repeating code patterns and type safety
Among the primary reasons for developing Slonik, was the motivation to reduce the repeating code patterns and add a level of type safety. This is primarily achieved through the methods such as one, many, etc. But what is the issue? It is best illustrated with an example.
Suppose the requirement is to write a method that retrieves a resource ID given values defining (what we assume to be) a unique constraint. If we did not have the aforementioned convenience methods available, then it would need to be written as:
// @flow
import {
sql
} from 'slonik';
import type {
DatabaseConnectionType
} from 'slonik';opaque type DatabaseRecordIdType = number;const getFooIdByBar = async (
connection: DatabaseConnectionType,
bar: string
): Promise<DatabaseRecordIdType> => {
const fooResult = await connection.query(sql`
SELECT id
FROM foo
WHERE bar = ${bar}
`); if (fooResult.rowCount === 0) {
throw new Error('Resource not found.');
} if (fooResult.rowCount > 1) {
throw new Error('Data integrity constraint violation.');
} return fooResult[0].id;
};
oneFirst method abstracts all of the above logic into:
const getFooIdByBar = (
connection: DatabaseConnectionType,
bar: string
): Promise<DatabaseRecordIdType> => {
return connection.oneFirst(sql`
SELECT id
FROM foo
WHERE bar = ${bar}
`);
};oneFirst throws:
NotFoundErrorif query returns no rowsDataIntegrityErrorif query returns multiple rowsDataIntegrityErrorif query returns multiple columns
This becomes particularly important when writing routines where multiple queries depend on the previous result. Using methods with inbuilt assertions ensures that in case of an error, the error points to the original source of the problem. In contrast, unless assertions for all possible outcomes are typed out as in the previous example, the unexpected result of the query will be fed to the next operation. If you are lucky, the next operation will simply break; if you are unlucky, you are risking data corruption and hard to locate bugs.
Furthermore, using methods that guarantee the shape of the results, allows us to leverage static type checking and catch some of the errors even before they executing the code, e.g.
const fooId = await connection.many(sql`
SELECT id
FROM foo
WHERE bar = ${bar}
`);await connection.query(sql`
DELETE FROM baz
WHERE foo_id = ${fooId}
`);
Static type check of the above example will produce a warning as the fooId is guaranteed to be an array and the binding of the last query is expecting a primitive value.
Protecting against unsafe connection handling
Slonik only allows to check out a connection for the duration of the promise routine supplied to the pool#connect()method.
The primary reason for implementing onlythis connection pooling method is because the alternative is inherently unsafe, e.g.
// Note: This example is using unsupported API.const main = async () => {
const connection = await pool.connect(); await connection.query(sql`SELECT foo()`); await connection.release();
};
In this example, if SELECT foo() produces an error, then connection is never released, i.e. the connection remains to hang.
A fix to the above is to ensure that connection#release() is always called, i.e.
// Note: This example is using unsupported API.const main = async () => {
const connection = await pool.connect(); let lastExecutionResult; try {
lastExecutionResult = await connection.query(sql`SELECT foo()`);
} finally {
await connection.release();
} return lastExecutionResult;
};
Slonik abstracts the latter pattern into pool#connect() method.
const main = () => {
return pool.connect((connection) => {
return connection.query(sql`SELECT foo()`);
});
};Connection is always released back to the pool after the promise produced by the function supplied to connect() method is either resolved or rejected.
Protecting against unsafe transaction handling
Just like in the unsafe connection handlingdescribed above, Slonik only allows to create a transaction for the duration of the promise routine supplied to the connection#transaction() method.
connection.transaction(async (transactionConnection) => {
await transactionConnection.query(sql`INSERT INTO foo (bar) VALUES ('baz')`);
await transactionConnection.query(sql`INSERT INTO qux (quux) VALUES ('quuz')`);
});This pattern ensures that the transaction is either committed or aborted the moment the promise is either resolved or rejected.
Protecting against unsafe value interpolation 🦄
SQL injections are one of the most well known attack vectors. Some of the biggest data leaks were the consequence of improper user-input handling. In general, SQL injections are easily preventable by using parameterization and by restricting database permissions, e.g.
// Note: This example is using unsupported API.connection.query('SELECT $1', [
userInput
]);
In this example, the query text (SELECT $1) and parameters (value of the userInput) are passed to the PostgreSQL server where the parameters are safely substituted into the query. This is a safe way to execute a query using user-input.
The vulnerabilities appear when developers cut corners or when they do not know about parameterization, i.e. there is a risk that someone will instead write:
// Note: This example is using unsupported API.connection.query('SELECT \'' + userInput + '\'');
As evident by the history of the data leaks, this happens more often than anyone would like to admit. This is especially a big risk in Node.js community, where predominant number of developers are coming from frontend and have not had training working with RDBMSes. Therefore, one of the key selling points of Slonik is that it adds multiple layers of protection to prevent unsafe handling of user-input.
To begin with, Slonik does not allow to run plain-text queries.
connection.query('SELECT 1');The above invocation would produce an error:
TypeError: Query must be constructed using
sqltagged template literal.
This means that the only way to run a query is by constructing it using sql tagged template literal, e.g.
connection.query(sql`SELECT 1`);To add a parameter to the query, user must use template literal placeholders, e.g.
connection.query(sql`SELECT ${userInput}`);Slonik takes over from here and constructs a query with value bindings, and sends the resulting query text and parameters to the PostgreSQL. As sql tagged template literal is the only way to execute the query, it adds a strong layer of protection against accidental unsafe user-input handling due to limited knowledge of the SQL client API. I challenge you to think of an SQL injection scenario within the bounds of the API surface that you have been introduced to.
As Slonik restricts user’s ability to generate and execute dynamic SQL, it provides helper functions used to generate fragments of the query and the corresponding value bindings, e.g. sql.identifier, sql.tuple, sql.tupleList, sql.unnest and sql.valueList. These methods generate tokens that the query executor interprets to construct a safe query, e.g.
connection.query(sql`
SELECT ${sql.identifier(['foo', 'a'])}
FROM (
VALUES ${sql.tupleList([['a1', 'b1', 'c1'], ['a2', 'b2', 'c2']])}
) foo(a, b, c)
WHERE foo.b IN (${sql.tuple(['c1', 'a2'])})
`);This (contrived) example generates a query equivalent to:
SELECT "foo"."a"
FROM (
VALUES
($1, $2, $3),
($4, $5, $6)
) foo(a, b, c)
WHERE foo.b IN ($7, $8)That is executed with the parameters provided by the user.
Finally, if there comes a day that you mustgenerate the whole or a fragment of a query using string concatenation, then Slonik provides sql.raw method. However, even when using sql.raw, we derisk the dangers of generating SQL by allowing developer to bind values only to the scope of the fragment that is being generated, e.g.
sql`
SELECT ${sql.raw('$1', ['foo'])}
`;Allowing to bind values only to the scope of the SQL that is being generated reduces the amount of code that the developer needs to scan in order to be aware of the impact that the generated code can have. Continue reading Using sql.raw to generate dynamic queries to learn further about sql.raw.
To sum up, Slonik is designed to prevent accidental creation of queries vulnerable to SQL injections.
Interceptors
Up to now we have talked about the design decisions behind the Slonik API. However, one of my favourite features of Slonik is that you can add functionality to Slonik by adding interceptors (comparable to Express.js middleware).
Interceptor is an object that implements methods that can change the behaviour of the database client at different stages of the connection life-cycle:
afterPoolConnection– Executed after a connection is acquired from the connection pool (or a new connection is created).afterQueryExecution–afterQueryExecutionmust return the result of the query, which will be passed down to the client. UseafterQueryto modify the query result.beforeQueryExecution– This function can optionally return a direct result of the query which will cause the actual query never to be executed.beforeConnectionPoolRelease– Executed before connection is released back to the connection pool.transformQuery– Executed beforebeforeQueryExecution. Transforms query.
Interceptors are executed in the order they are added.
Built-in interceptors
Community can create their own interceptors. Meanwhile, Slonik comes with couple of in-built interceptors:
- Field name transformation interceptor – formats query result field names (underscore casing to camel case). This interceptor removes the necessity to alias field names.
- Query normalization interceptor – Normalizes the query by removing comments and whitespaces.
- Benchmarking interceptor – Summarizes all queries that were run during the life-time of the connection.
Inserting large number of rows
Inserting large datasets safely and fast into the database is a big part of working with the database. The utilities provided by Slonik abstract generation of code fragments that are used to do just that, e.g.
Slonik provides sql.tupleList helper function to generate a list of tuples that can be used in the INSERT values expression, e.g.
await connection.query(sql`
INSERT INTO (foo, bar, baz)
VALUES ${sql.tupleList([
[1, 2, 3],
[4, 5, 6]
])}
`);Produces:
{
sql: 'INSERT INTO (foo, bar, baz) VALUES ($1, $2, $3), ($4, $5, $6)',
values: [
1,
2,
3,
4,
5,
6
]
}However, there are 2 downsides to this approach:
- The generated SQL is dynamic and will vary depending on the input. (You will not be able to track query stats. Query parsing time increases with the query size.)
- There is a maximum number of parameters that can be bound to the statement (65535).
As an alternative, we can use sql.unnest to create a set of rows using unnset. Using the unnset approach requires only 1 variable per every column; values for each column are passed as an array, e.g.
await connection.query(sql`
INSERT INTO (foo, bar, baz)
SELECT *
FROM ${sql.unnest(
[
[1, 2, 3],
[4, 5, 6]
],
[
'integer',
'integer',
'integer'
]
)}
`);Produces:
{
sql: 'INSERT INTO (foo, bar, baz) SELECT * FROM unnest($1::integer[], $2::integer[], $2::integer[])',
values: [
[
1,
4
],
[
2,
5
],
[
3,
6
]
]
}Inserting data this way ensures that the query is stable and reduces the amount of time it takes to parse the query.
What is the next big feature for Slonik?
The way that Slonik is using tagged template literals to generate code fragments and safely bind parameter values is particularly exciting. Therefore, I am exploring feasibility of allowing community to bring their own code-generating extensions that integrate into Slonik template language. These extensions will allow to abstract business-specific fragments of code (e.g. dynamic WHERE conditions for a particular business requirement); big development teams can use this pattern to restrict any use of raw.sql in the main codebase. This enables separating integration and code generation tests.
Follow this issue to see how this feature evolves:
https://github.com/gajus/slonik/issues/21
Time to install Slonik
Currently, Slonik is developed primarily based on the requirements that I have personally come across during the many years of using RDBMSes. Now I am reaching out into the community, gathering feedback and continue working to make Slonik the industry standard Node.js client for PostgreSQL. Therefore, if you are going to use PostgreSQL with Node.js, then install Slonik and give it a go.
Comments
Post a Comment