MongoDB is a popular database that works without imposing any kind of schema. The data is stored in a JSON-like format and can contain different kinds of structures. For example, in the same collection we can have the next two documents:
To get the best out of MongoDB, you have to understand and follow some basic database design principles. Before getting to some design tips, we have to first understand how MongoDB structures the data.
How Data Is Stored in MongoDB
Unlike a traditional RDBMS, MongoDB doesn’t work with tables, rows, and columns. It stores data in collections, documents, and fields. The diagram below explains the structure compared to an RDBMS:
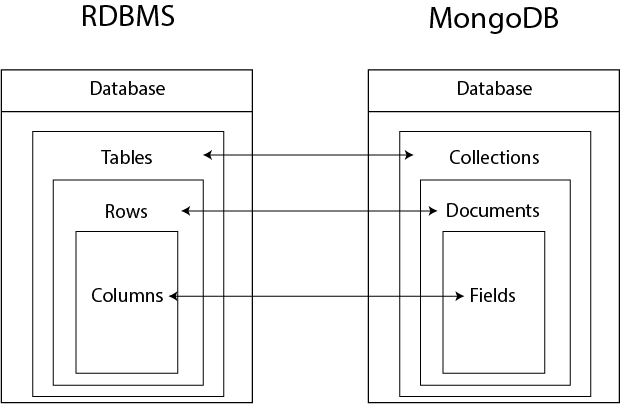
Database Design Tips and Tricks
Smart Document Management: Normalization vs Denormalization
Given the fact that MongoDB works with documents, it’s very important to understand the concepts of normalization and denormalization. These two define the way MongoDB stores the data.
Normalization - normalizing means storing data into multiple collections with references between them. The data is defined once, making the writing tasks (update) easy. When it comes to reading tasks, normalization has its downsides. If you want to receive data from multiple collections, you have to perform multiple queries making the reads slower.
Denormalization - this is storing multiple data embedded in a single document. It will perform better on reads but will be slower on writes. This way of storing data will also take up more space.
Before you choose between the two ways of storing data, asses on the way you will use the database.
On one hand, if you have a database that doesn’t need regular updates, has small documents that grow slowly in size, immediate consistency on the update is not very important, but you need a good performance on reads, then denormalization may be the smart choice.
On the other hand, if your database has large documents with constant updates and you want good performance on writes, then you may want to consider normalization.
1:N Relationships
Modeling “One-to-N” relations in MongoDB is more nuanced than an RDBMS. Many beginners fall into the trap of embedding an array of documents into the parent table and this is not always the best solution. As we’ve seen in the first tip, knowing when to normalize or denormalize is very important. So, before starting, everyone should consider the cardinality of the relation. Is it “one-to-few”, “one-to-many” or “one-to-squillions”? Each relationship will have a different modeling approach.
For example, below we have a “One-to-few” cardinality example. The best choice here is to embed the N side (addresses) in the parent document (persons):
In a “One-to-many” example, we may consider two collections, the product collection, and the parts collection. Every part will have a reference “ObjectID” that will be present in the product collection.
Schema Visualization
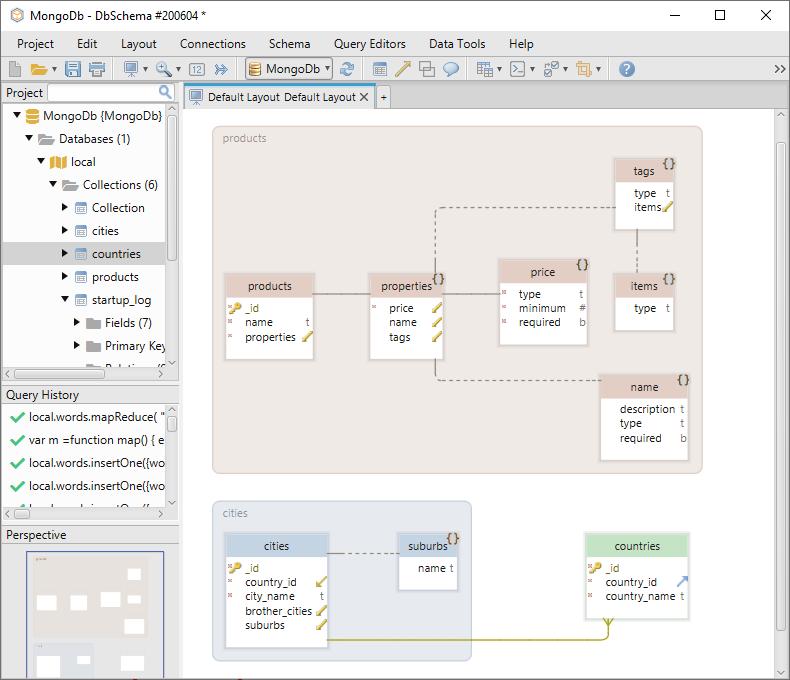
Even though MongoDB is “schemaless”, there are still ways to visualize the collections as diagrams. Being able to view the diagram will have a great impact on the way you plan your MongoDB design.
DbSchema is a tool that does this job very well. It will deduce the schema by reading the collections & documents just like in the image below. Further, you are able to modify the objects right in the diagram just by clicking on them.
In DbSchema you can also create foreign keys for MongoDB. They will be created only locally for design purposes. You can download DbSchema from here.
Smart Indexing
To maintain a good performance of your database, you have to implement a smart indexing system that will streamline your write and read operations. Knowing the indexing advantages and limitations for MongoDB is very important in doing so. Keep in mind that MongoDB has a limit of 32MB in holding documents for a sort operation. If you don’t use indexes, then the database is forced to hold a various amount of documents (depending on your database) while sorting. If MongoDB hits the limitation, then the database will return an error or an empty set.
Conclusion
A thorough understanding of MongoDB combined with a clear view of what you want to achieve with the database is the recipe for good database design.
Comments
Post a Comment