Unfortunately, the Sequelize documentation did not cover this specific topic and multiple stackoverflow posts had to save the day. To save you time, I decided to write a post, summarizing my approach and some helpful tips and tricks.
The Sequelize documentation states:
Sequelize will setup a connection pool on initialization so you should ideally only ever create one instance per database if you’re connecting to the DB from a single process.
This means, that we will need to run a new Sequelize instance for every database we want to connect to our server. The easiest and most flexible way to do this is to declare multiple databases in our config.js and then loop over these databases in the file handling our database connections (in my case this is the index.js of my models folder).
module.exports = {
/**Declaration of databases for my development environment**/
"development": {
"databases": {
"Database1": {
"database": process.env.RDS_DATABASE1, //you should always save these values in environment variables
"username": process.env.RDS_USERNAME1, //only for testing purposes you can also define the values here
"password": process.env.RDS_PASSWORD1,
"host": process.env.RDS_HOSTNAME1,
"port": process.env.RDS_PORT1,
"dialect": "postgres" //here you need to define the dialect of your databse, in my case it is Postgres
},
"Database2": {
"database": process.env.RDS_DATABASE2,
"username": process.env.RDS_USERNAME2,
"password": process.env.RDS_PASSWORD2,
"host": process.env.RDS_HOSTNAME2,
"port": process.env.RDS_PORT2,
"dialect": "mssql" //second database can have a different dialect
},
},
}
}
config.js
Here we declared two databases — The Postgres Database “Database1” and the MSSQL Database “Database2” — and their credentials for the connection. Now let’s have a look how to read in these declarations and connect to the databases.
const Sequelize = require('sequelize');
const env = process.env.NODE_ENV || 'development';
//Load the configuration from the config.js
const config = require(`${__dirname}/../config/config.js`)[env];
//Create an empty object which can store our databases
const db = {};
//Extract the database information into an array
const databases = Object.keys(config.databases);
//Loop over the array and create a new Sequelize instance for every database from config.js
for(let i = 0; i < databases.length; ++i) {
let database = databases[i];
let dbPath = config.databases[database];
//Store the database connection in our db object
db[database] = new Sequelize( dbPath.database, dbPath.username, dbPath.password, dbPath );
}
/**Load Sequelize Models**/
index.js
The “db” object now contains information on how to connect to all databases configured in our config.js, but does not contain information about the models in the database, consequently not being able to make correct SQL queries. To give the “db” object the necessary model information, we need to read the information from our model files and add it to the object. To understand the next few lines of code, we first need to have a look at my folder structure. The index.js is located in the models folder, which has two subdirectories for models of both databases from my config.js:
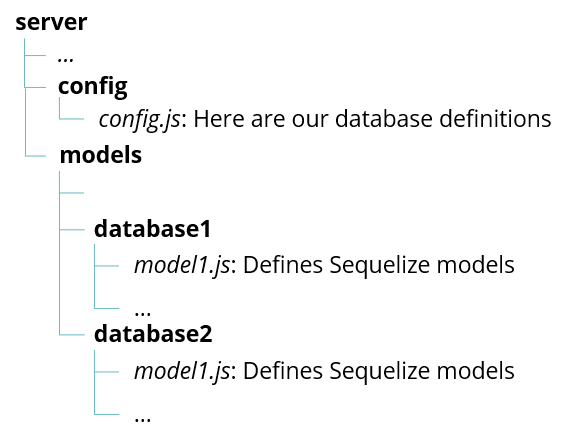
Now lets add the models from both directories to our “db” object in the index.js:
const fs = require('fs');
const path = require('path');
const Sequelize = require('sequelize');
const basename = path.basename(module.filename);
const env = process.env.NODE_ENV || 'development';
const config = require(`${__dirname}/../config/config.js`)[env];
const db = {};
const databases = Object.keys(config.databases);
/** Add Databases**/
for(let i = 0; i < databases.length; ++i) {
let database = databases[i];
let dbPath = config.databases[database];
db[database] = new Sequelize( dbPath.database, dbPath.username, dbPath.password, dbPath );
}
/**Add the Database Models**/
//Add models from database1 folder
fs
.readdirSync(__dirname + '/database1')
.filter(file =>
(file.indexOf('.') !== 0) &&
(file !== basename) &&
(file.slice(-3) === '.js'))
.forEach(file => {
const model = db.ebdb.import(path.join(__dirname + '/database1', file));
db[model.name] = model;
});
// Add models from database2 folder
fs
.readdirSync(__dirname + '/database2')
.filter(file =>
(file.indexOf('.') !== 0) &&
(file !== basename) &&
(file.slice(-3) === '.js'))
.forEach(file => {
const model = db.easyconnect.import(path.join(__dirname + '/database2', file));
db[model.name] = model;
});
Object.keys(db).forEach(modelName => {
if (db[modelName].associate) {
db[modelName].associate(db);
}
});
module.exports = db;
index.js
Now we can require our models in our controllers as usual:
const model1= require('../models').model1;
Congratulations! You added multiple databases to your NodeJS server and made them accessible. Now let’s talk about the tricky part: migrations and seeders
Sequelize is currently not supporting multiple migration folders and is not able to distinguish, which migrations should be ran in each database by itself, if all migration files are kept in one folder. While there are multiple ways to deal with this problem — e.g. manually setting migration filepaths in the sequelize cli — I found the approach using separate options files and npm scripts the most productive:
First lets expand our config.js with environments for migrating and seeding our databases. Every environment then only contains data for one specific database, so we can explicitly define to which database we want to connect:
module.exports = {
"development": {
"databases": { /** our database declarations from before**/}
},
// Special environment only for Database1
"Database1": {
"database": process.env.RDS_DATABASE1, //you should always save these values in environment variables
"username": process.env.RDS_USERNAME1, //only for testing purposes you can also define the values here
"password": process.env.RDS_PASSWORD1,
"host": process.env.RDS_HOSTNAME1,
"port": process.env.RDS_PORT1,
"dialect": "postgres" //here you need to define the dialect of your databse, in my case it is Postgres
},
// Special environment only for Database2
"Database2": {
"database": process.env.RDS_DATABASE2,
"username": process.env.RDS_USERNAME2,
"password": process.env.RDS_PASSWORD2,
"host": process.env.RDS_HOSTNAME2,
"port": process.env.RDS_PORT2,
"dialect": "mssql" //second database can have a different dialect
},
config.js
In the next steps we create new Sequelize options files — similar to our .sequelizerc file — for every database. So lets create these two files in the directory of our package.json file:
- .sequelize-database1
- .sequelize-database2
In these files, we can define in which directory our config, models, migrations and seeders are stored:
const path = require('path');
module.exports = {
"config": path.resolve('./server/config', 'config.js'),
"models-path": path.resolve('./server/models'),
"seeders-path": path.resolve('./server/seeders/database1'),
"migrations-path": path.resolve('./server/migrations/database1')
};
.sequelize-database1
const path = require('path');
module.exports = {
"config": path.resolve('./server/config', 'config.js'),
"models-path": path.resolve('./server/models'),
"seeders-path": path.resolve('./server/seeders/database2'),
"migrations-path": path.resolve('./server/migrations/database2')
};
.sequelize-database2
Finally we can use these options files in npm scripts, that run our migrations oder seeders. Therefore we need to add some lines to the scripts section of package.json file:
{
"scripts": {
"sequelize:database1:migrate": "sequelize --options-path ./.sequelize-database1 --env database1 db:migrate",
"sequelize:database1:migrate:undo": "sequelize --options-path ./.sequelize-database1 --env database1 db:migrate:undo",
"sequelize:database1:seed:all": "sequelize --options-path ./.sequelize-database1 --env database1 db:seed:all",
"sequelize:database2:migrate": "sequelize --options-path ./.sequelize-database2 --env database2 db:migrate",
"sequelize:database2:migrate:undo": "sequelize --options-path ./.sequelize-database2 --env database2 db:migrate:undo",
"sequelize:database2:seed:all": "sequelize --options-path ./.sequelize-database2 --env database2 db:seed:all",
},
}
package.json
The scripts use the two .sequelize-database1, .sequelize-database2 options files to determine the location of the configuration, models, migrations and seeder directories and set the correct environment for reading configurations from the config.js file.
You can run the scripts with an npm run command from the command line:
npm run sequelize:database1:migrate
I hope this article could help you setting up multiple database connections to a single NodeJS server with Sequelize. If you have any questions, feel free to ask them in the comment section.
Comments
Post a Comment